MCP transports, decided
Table of contents
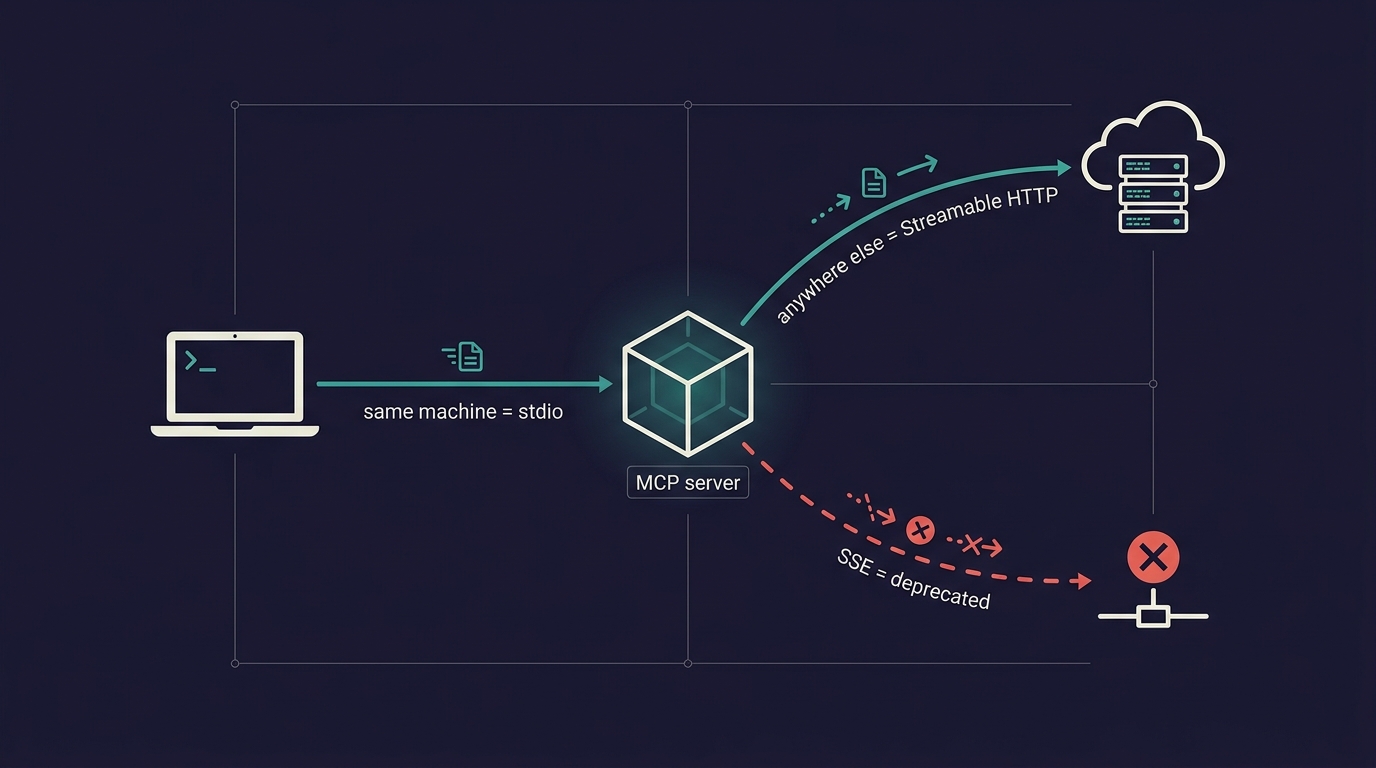
The transport is decided by where the other end has to sit: same machine as the client takes stdio, anywhere else takes Streamable HTTP, and SSE is the deprecated route you migrate off.
I lost an afternoon to this once. Then I watched two other people lose theirs. Every one of us came out the far side having picked the exact MCP transport we’d have picked in ten seconds if someone had just stated the rule up front.
So I’m not going to hold the answer hostage for suspense, because the whole point of this post is that the answer takes ten seconds. There are three MCP transports. One is deprecated and you are migrating off it whether you’ve admitted that yet or not. The choice between the remaining two is not a taste call. It’s decided by where your server runs. Same machine as the client: stdio. Anywhere else: Streamable HTTP. SSE: a migration ticket, never a new build. That’s the rule.
This post is narrow on purpose. Pick the transport, don’t bleed a day doing it. The genuinely hard stuff (auth, session lifecycle, what falls over the moment a second user shows up) sits on top of that choice, and it’s its own set of posts. Naming that boundary now is what keeps this one from sprawling into a survey of everything that touches a transport.
stdio: still the local default, even if I’ve stopped reaching for it
stdio gets underrated because it looks too simple to be the answer. It is the answer, for local.
Mechanically it’s a pipe. The client spawns your server as a child process and talks to it over stdin and stdout: newline-delimited JSON-RPC, one message per line. No port. No network. If the server runs on the same machine as the agent (a CLI wrapping local tooling, something that reads your filesystem), this is correct and you can stop thinking about it. The process boundary is your security boundary, and the OS already does that isolation for free. You inherit the user’s environment and credentials because you are a process the user launched. That privilege level is exactly what you want for a local tool, and exactly the liability you don’t want the instant the thing is reachable from anywhere else.
I covered why the April OX Security stdio RCE was a deployment story and not a protocol one in MCP isn’t dead, so I won’t re-litigate it here. The short version that matters for transport choice: a stdio server reachable beyond the local machine is a misconfiguration, not a flaw to harden around. If you’re reaching for a tunnel to expose a stdio server to a remote client, you picked the wrong transport, and the next section is the one you wanted.
The thing that’ll really cost you the afternoon is dumber than any security story. stdout is the wire. It is not “where logs go.” It is the literal protocol channel, and anything you print to it corrupts JSON-RPC. One stray console.log. One library that helpfully logs a banner to stdout on init. The client receives a JSON-RPC line with your debug string wedged into the middle of it, and you get a parse error, a dead session, and a stack trace pointing at nothing. The fix is one rule held without exception: logs go to stderr, all of them, always. This is the single most common “my local MCP server mysteriously won’t connect” cause I have watched people hit, and it has nothing to do with MCP, the SDK, or your tool code. The wire and your log stream are the same file descriptor until you make them not be. Make them not be on line one.
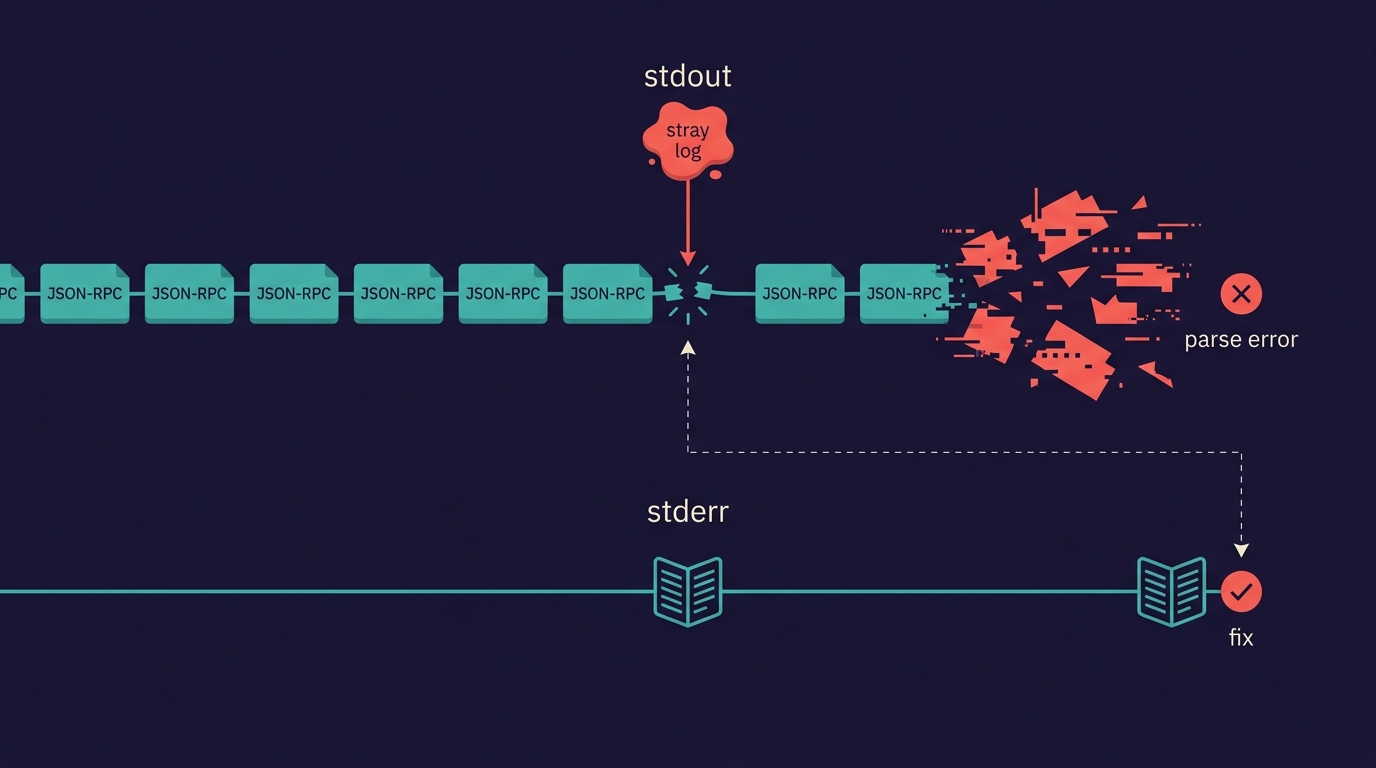
stdout is the wire. One stray log line written to it wedges into the JSON-RPC stream and corrupts everything downstream. Logs go to stderr, all of them, always.
One caveat before we leave local. I have not built or shipped a stdio server in over a year. Not because stdio got worse. Because “local” keeps describing less of what I make. The ground under it is getting squeezed from two sides. Anything meant to be reached from off my machine is remote by definition and was never a stdio question. And the local capability I’d once have wrapped in a stdio server, I now write as a skill or call as a CLI the agent already carries. On that side stdio isn’t losing to another transport. It’s losing to skills and pre-installed tooling, which is the delivery-channel fight I picked in that same post, not a transport one.
None of that makes stdio a worse default. By raw count it is still most of the ecosystem, and the filesystem and git and browser tools that touch your actual machine are local by design and staying there. The rule holds exactly as written: same machine, stdio. What changed is how rarely I am on the same machine as the thing I am building.
SSE: deprecated, and you’re migrating off it
There used to be two remote transports. The original was HTTP+SSE: a GET that opened a long-lived Server-Sent Events stream for everything the server pushed back, plus a separate POST endpoint for everything the client sent. Two channels, both held open, correlated on the client side.
It’s deprecated. The spec replaced it with Streamable HTTP in the 2025-03-26 revision, and this is the hard kind of deprecated, not the soft kind that lingers usefully for years. SSE has a real architectural problem that Streamable HTTP exists to solve: it needs a persistent, stateful connection held open for the entire life of the session, pinned to one exact instance. It doesn’t survive a load balancer that decides to move you. It’s outright fatal on anything serverless, where the worker spins down between requests and takes your stream down with it.
If you have an SSE server today, the migration is small in the only way that counts: your tool logic doesn’t change. You swap the transport class (every maintained SDK ships a Streamable HTTP server you can drop in) and run both endpoints side by side during cutover so old clients don’t break the day you flip the switch. Point new traffic at the new transport, watch the old endpoint go quiet, delete it.
The reason to stop putting this off: SSE works on your laptop and on a single always-on box, so it feels fine right up until it isn’t. Then you move to anything that load-balances or scales to zero, the stream drops mid-session with no clean error, and you debug it as a flaky network for an afternoon. It’s not the network. It’s the transport.
Streamable HTTP: the one you target
Streamable HTTP is the answer for everything that isn’t a local subprocess. One endpoint. The client POSTs its JSON-RPC, and the server chooses, per request, how to answer: a plain JSON response for a quick request and reply, or an upgrade of that same connection to an SSE stream when a particular call needs to push progress back. Streaming still exists when a tool genuinely needs it. It’s just no longer the mandatory always-open default.
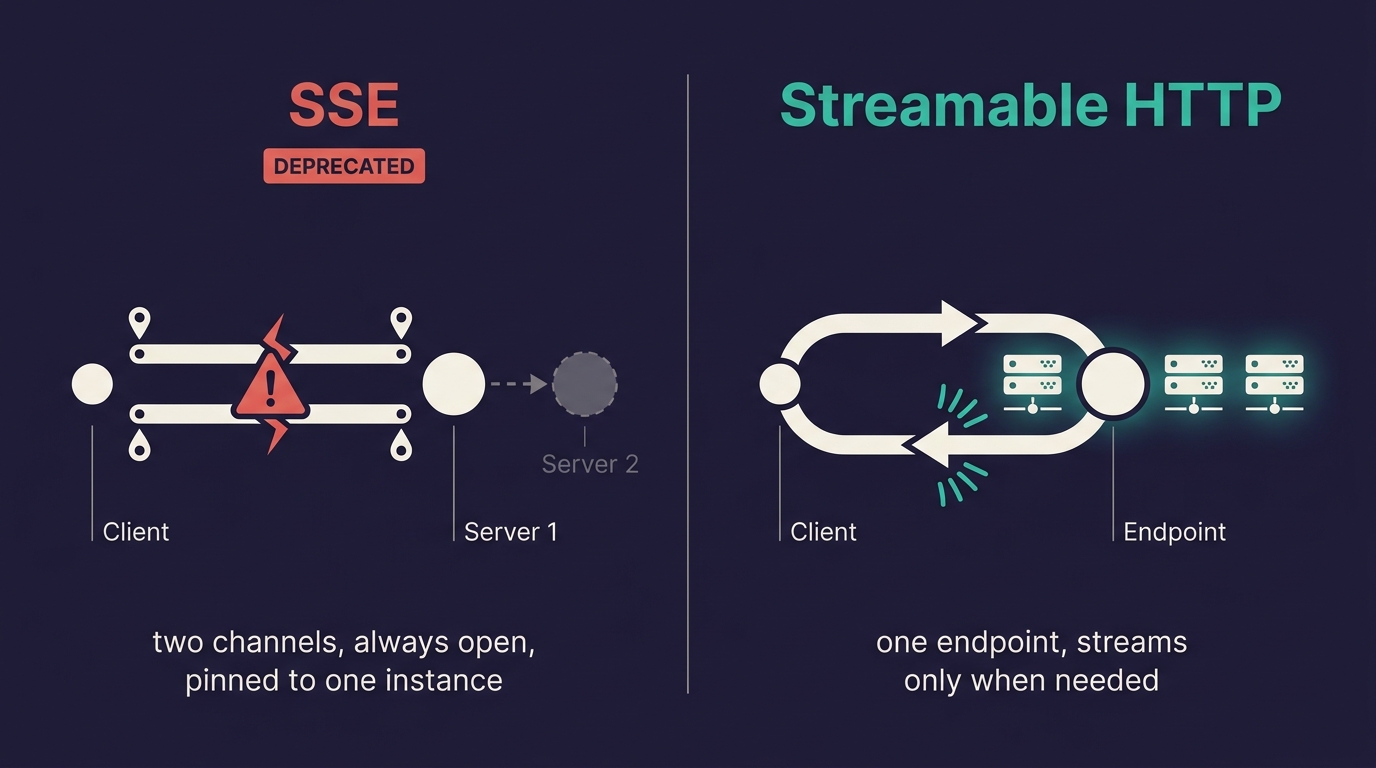
SSE (left) holds two channels open for the whole session, pinned to one instance, and dies the moment that instance moves. Streamable HTTP (right) is one endpoint per request that streams only when a call needs it, so a load balancer or a cold start stops mattering.
That one change is the entire reason this is the future. A simple tool call becomes a normal HTTP round trip (request, response, connection closed, nothing pinned), so load balancers, cold starts, and a request landing on a different instance than the last one all stop mattering. As long as your session state lives somewhere shared instead of in process memory. That clause is load-bearing, but it’s a sessions problem, not a transport one, and this post stops at the transport.
Every remote MCP server I run ships on Cloudflare Workers as Streamable HTTP, and the fit isn’t a coincidence. A Worker has no long-lived process to hang an SSE stream off of in the first place. It spins up to handle one request and goes away. SSE’s “keep this socket open for the whole session” model is a non-starter on that runtime by construction. When the platform is request-scoped, the request-scoped transport isn’t a preference. It’s the one that physically works.
The MCP transport choice is settled; the hard part sits on top
Say the rule one more time, in one breath: same machine as the client, stdio; anywhere else, Streamable HTTP; SSE is a migration ticket, never a new build. The agonising I keep watching comes from treating a settled question as an open one. The transport layer is not where your judgment goes. Where your server runs decides it for you.
None of this is standing still, and it’s worth knowing which way it moves, even though it isn’t final yet. The release candidate for the next revision stops treating a transport as a channel and starts treating it as a binding: something that defines only how messages get framed and delivered, not what they mean. It pulls session state and server-initiated calls off the wire, so any request can land on any instance. That is not a fourth transport. A WebSocket one was actually proposed (SEP-1288) and shelved, and the roadmap says no new transports this cycle. The set of transports isn’t changing. The contract under them is, and it moves in exactly one direction: session pulled off the wire, nothing pinned, the same rule this post already gave you only getting harder to argue with. Local is stdio. Remote is Streamable HTTP. That’s still the whole decision.
Everything sitting on top of the transport is where the judgment actually lives. Auth, because Streamable HTTP just put you on the open internet and now you owe the thing a real authorization story. Sessions, and what that id is for, when you genuinely need it, and how to carry state without re-pinning yourself to a single box. Behaviour under a second concurrent user that the happy-path tutorials never had to survive. And where the thing actually runs once it’s remote, Workers or Lambda or the growing list behind them, each making a different bet on cold starts and where your session state lives. That one is its own post, later in this series.
The transport took me ten seconds once I knew the rule. The auth and session story is the part I actually had to think about. Spend your judgment there.
May the right transport find you before the lost afternoon does…