No, MCP servers aren't dead (and here's the 2007 reason why)
Table of contents

‘MCP is dead,’ goes the call. The fight it misses is the same one from Part 1, with no gatekeeper: an MCP server updates like a website the moment the maintainer deploys, while a skill sits on your disk like an app you downloaded once.
In Part 1 I argued that mobile won the platform war on distribution, not capability, and I closed on one line: in mobile, the brake we couldn’t control was the gatekeeper.
In agent tooling there is no gatekeeper. No App Store sits between me and the people who run my tools, no review queue taking a 30 percent cut on the way through. So the obvious read this spring was the loud one: MCP is dead. With no gatekeeper to fight, you don’t need its machinery at all; a plain CLI or a downloaded skill does the job, and MCP is dead weight on the way out.
The brake did not disappear, it changed shape. Update friction is still the brake, and right now MCP releases it while skills, by default, do not. That axis is the one the death debate keeps skipping.
The “MCP is dead” wave is real
The people making the call are serious, and worth naming fairly.
Eric Holmes put “MCP is dead. Long live the CLI” on the front page of Hacker News in February 2026, and it stuck. Garry Tan has been building a CLI-shaped replacement and saying the quiet part out loud. Denis Yarats, Perplexity’s CTO, has talked about deprioritizing MCP internally. Pieter Levels echoed the sentiment on X to a large audience. Walk any thread on HN right now and the temperature is strongly anti-MCP.
Three real complaints sit under the noise, and each deserves its strongest form:
- “MCP eats your context.” Stand up three servers and the agent is two-thirds full before it does any work.
- “MCP is insecure.” A remote-code-execution hole in the default transport, and up to a third of public servers running wide open.
- “Everyone is moving to skills and CLIs.” The scoreboard reads like an exodus, and the loudest voices are credible ones.
Every one is true at the level it is usually stated. None is a death sentence, because all three measure the wrong axis.
The lens
I built this lens in Part 1 and will not re-derive it. The short version: when software’s value is the maintainer’s evolving logic rather than some irreplaceable device capability, the platform that controls the delivery and update channel wins. Web versus mobile was Exhibit A. The web always had the better channel, the maintainer could ship a fix on Tuesday and every user had it on Tuesday, and mobile only won because the store seized the channel and the install button out from under it. Capability was never the deciding axis. Update friction was. Read Part 1 if you want the full argument; this post assumes it.
The argument nobody is making
An MCP server is a website. You deploy a new version, the client fetches the new tool list on its next call, and every user is current with zero action. They did nothing on their end; the new behavior is just there the next time they invoke a tool. That is the maintainer at the steering wheel of the runtime, the seat the web held over mobile.
A skill behaves like an app you downloaded. The default install is to clone or copy it into a local directory, and from that moment the user owns that copy. It sits on their disk at the version they fetched, and it stays there.
None of this means a skill’s maintainer cannot push an update. Of course you can. You push to GitHub like anything else, an npx-style skill pulls the latest on every run, CI keeps a copy fresh. The maintainer can always publish.
The argument is about update friction and what the default is. With MCP, auto-fetch-the-latest is how the protocol works, not a thing you opt into. With skills, getting every user back to current needs a re-pull, an npx path, or a plugin channel, and none of those is the default across agents. The open question is whether the client picks up the new version without the user doing anything. For MCP, yes by construction. For skills, usually no, by default. That gap, between “the maintainer fixed it” and “the user has the fix,” is the asymmetry. Plenty of people have clocked that MCP stays current; they file it as a convenience for the user. Put the maintainer’s seat at the centre instead, and update friction stops being a convenience and turns into the axis that decides the whole fight.
I am not arguing this from the cheap seats. I run all three MCP primitives in production. mcplex is Code Mode in production, a single server that generates code over raw tool-calling. Smriti is the memory and skills-knowledge layer, the stable stuff the agent learns once. Parakh is a live-access MCP that hits real third-party APIs through a credential-injection interceptor, so the code that runs never sees the secrets. That is the seat I argue from, evidence rather than a pitch. Back to the complaints.
Argument 1: “MCP eats your context”
On the models shipping as I write this, a standard three-server setup can eat roughly 72 percent of the context window before the agent does a single useful thing. The numbers are genuinely bad, which is why this complaint gets repeated the most. Three servers on a 200K model is something like 143K tokens spent on tool definitions alone. If that is your baseline, the agent is exhausted before it starts, and declaring the protocol dead feels rational. The complaint is real enough that it spawned a category: part of why Agent Skills caught on this fast is that they load on demand instead of dumping everything into context the way a naive MCP server does.
That is an implementation default the protocol does not require, and two fixes for it already exist.
The first is tool search: the client defers the definitions and pulls only the handful the task needs, cutting tool-definition tokens by around 85 percent. The second goes further. The agent writes code against a generated API, so the definitions never sit in context at all. Cloudflare’s Code Mode reported a 99.9 percent cut: an API that would burn 1.17 million tokens as native definitions runs in about a thousand. Anthropic published the same pattern independently, measuring 150,000 tokens down to 2,000.
Both fixes share a limit: neither is the default. As of mid-2026, Claude Code is the only coding agent that ships tool search on by default; Codex and Copilot still have it open as feature requests. Code Mode is turnkey only on Cloudflare, who own the sandbox it needs to run generated code safely; everyone else gets the open-sourced SDK and the job of hosting it. So the death-callers measured something real: the default, which on most agents is still the naive one. The token problem is solved engineering that has not finished shipping, nothing like a dead protocol.
That is the pattern mcplex runs in production: one server, code generation, the tool surface staying small because the agent reaches for tools through code instead of holding all of them in its head. The ceiling the death-callers benchmarked is real on a default setup and gone on this one.
Argument 2: “MCP is insecure”
The receipts here are real and recent. In April 2026, OX Security disclosed a remote-code-execution flaw in the MCP stdio transport that touched a large share of SDK installs. Separately, analyses from Zuplo and Bloomberry have put the share of public MCP servers running with zero authentication somewhere in the 24 to 38 percent range. Those are point-in-time numbers as I write this, and not comfortable ones.
Both are deployment failures. The protocol caused neither, and the zero-auth number is the clearest tell. MCP does not make you invent new auth. It lets you reuse whatever your server already runs. If your API takes an API key, the MCP passes the key through. If it takes a user login, MCP speaks OAuth and rides the same flow your web app already uses. The servers sitting wide open did not get there because auth was hard. That is someone shipping a database to the public internet with no password and blaming the database.
The RCE is a transport choice. Expose a server remotely and you use Streamable HTTP, not stdio. And if your tools touch credentials, the tool code should never see the raw secret in the first place; you inject at the boundary and keep it out of the generated code’s reach. That interceptor pattern is the whole design of Parakh, because “the model might leak the key it can see” stops being a problem once it never sees the key.
And the security argument accidentally proves the other side’s point. The property that lets an MCP server be insecure, centralized control of what the client runs, is the same property that lets you patch it the moment you deploy. Find the hole on Tuesday and every client is fixed on the next call. A downloaded-and-owned skill cannot be patched out from under a vulnerability the same way; the bad copy sits on the user’s disk until something pulls a new one. The weakness the death-callers point to is the thing that makes MCP fixable.
The honest counter, because it cuts both ways: the same channel that pushes a fix instantly can push a malicious or breaking change instantly. Centralized control is a supply-chain risk as much as a patch advantage. That is the cost of the seat, and it does not change which seat ships fixes faster.
Argument 3: “Everyone is moving to skills and CLIs”
The scoreboard looks like a migration if you squint. The actual numbers: more than 9,400 public MCP servers, around 97 million monthly SDK downloads, the whole thing donated to the Linux Foundation. That is a hype peak settling into the trough of disillusionment, which is what every real technology does after its Gartner moment. The death narrative reads the trough as a tombstone.
The deeper mistake is treating skills and CLIs as a replacement. They relocate the work that fit MCP awkwardly. The split I would hand a junior engineer:
- Skills teach the agent. Stable knowledge, written once, that the agent should carry. How your codebase is laid out, your house style, the runbook for a deploy. Write-once, read-many.
- MCP lets the agent act. Data that changes between invocations. The current state of a ticket, a live API response, a row in a database that was different five minutes ago.
When someone “migrates” stable knowledge from a server into a skill, they did not prove MCP is dead. They found the right home for that one job. And the honest concession the other way: for some workloads relocation means MCP loses that job, and good, it should. The migration narrative confuses “found the right tool for each job” with “one tool killed the other.”
The bonus argument: “Then just use a CLI”
This is the real version of Holmes’ argument. A skill can act: bundle a curl command or a CLI, document the call, and the agent shells out to live data. So why run a server at all?
Take the REST-in-a-skill version first, because it falls apart cleanly. You have two ways to hand the agent the API contract. Freeze the endpoints and response shapes into the skill’s files, and they go stale the moment the API adds a field or moves a route, the maintainer-seat problem copied onto your own disk. Or have the skill fetch the OpenAPI spec at run time, and you have rebuilt context bloat, a whole spec dumped into the window on every call, the very complaint we started with. It is stale contract or blown context, with no third door. MCP dodges both: the server owns the contract so it is always current, and surfaces only the tools the task needs so it stays cheap.
The CLI version is much stronger, and I will not pretend otherwise. A good CLI encapsulates the contract and reads its own credentials, so the secret touches the CLI process and never the agent. The leak that sinks REST-in-a-skill is not a CLI problem; on credentials a CLI is as safe as MCP. For plenty of jobs it is the right tool, full stop. The real difference sits where this series always points: a CLI runs on the user’s machine and on the user’s version, an app you downloaded, current only until the maintainer ships the next release. The fix is an auto-upgrade step or running it through npx, which is fetch-latest delivery, the property that decides the fight. A remote MCP runs on the maintainer’s side and goes current the instant they deploy. The strongest form of the CLI argument wins by turning into MCP on the update channel.
The decision rule, from the field
The rule I actually use, earned by running these primitives rather than by watching the debate:
Stable knowledge you write once: a skill. Local action you are happy to version yourself, or run through npx: a CLI, documented by a skill. Action where the contract, the credential, or the execution has to stay current and maintainer-owned by default: MCP.
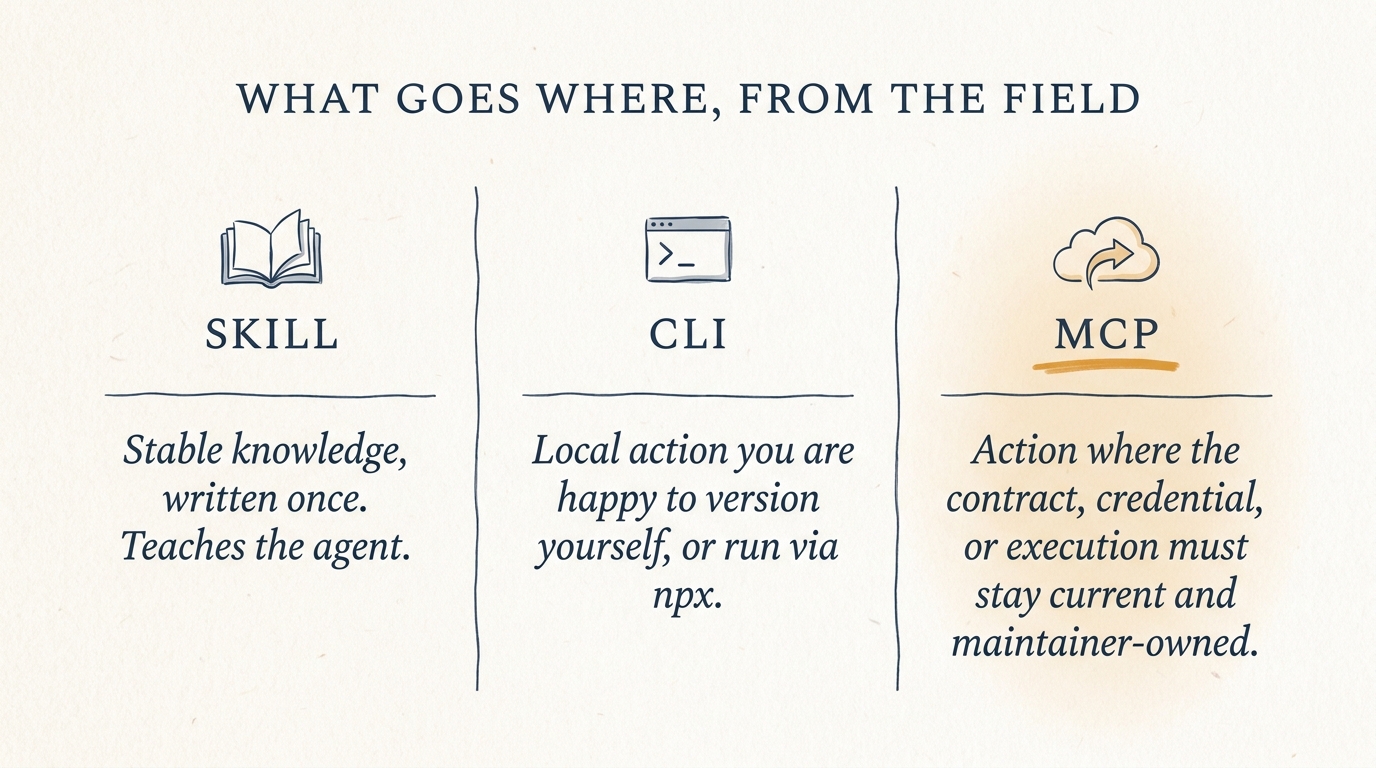
The split I would hand a junior engineer. The amber column is the only one where currency and the credential cannot live on the user’s machine.
No tribe, no funeral. Smriti teaches, a CLI takes the local jobs, mcplex acts where currency and the credential cannot live on the user’s machine. They never competed, because they were never doing the same job.
The asymmetry has an expiry date
A claim that cannot be falsified is not worth making, so here is where the maintainer-seat argument is strong and where it is on a clock.
Skills as a format converged fast. Claude Code shipped Agent Skills first, and the rest fell in line inside a few months: Codex in December 2025, then Antigravity, Gemini CLI, Cursor, and Copilot through early 2026. As a way to express “here is some knowledge for the agent,” skills are now a solved, cross-vendor standard.
The delivery channel has not converged. As of mid-2026 the default install for a skill is still clone or copy into a local directory and restart the agent. People symlink one skills folder across their agents to sync them by hand, which tells you the auto-update channel does not exist yet. The same artifact gets a plugin manifest and marketplace entry on one host and a user-level git clone on another. That is “downloaded once, becomes theirs, the client never fetches the maintainer’s latest.” I re-checked before publishing, because a change here would gut the thesis. It has not changed.
This is exactly the gap my post on agent-config debt was circling: we evolved from slash commands to MCP servers to skills, but the plumbing under those configs, including how updates reach the user, never caught up to the format.
The routes that would close the gap already exist. An npx-style fetch-on-invoke delivery would restore auto-update, so would a marketplace channel that pushes. But each is per-host, optional, and not the default on any serious agent today. So the falsifiable version: the asymmetry closes the moment fetch-latest delivery becomes the default for skills across all serious agents, not merely available on some. That condition reduces to “make the skill client behave like the MCP client”: to neutralize MCP’s advantage, skills have to copy MCP’s defining property. Skills are not losing permanently here. They just have not shipped the channel yet.
We have seen this movie
The first thing I now check in a new agent is whether it has fetch-latest delivery for skills. I want it badly, and I will not pretend I know which vendor ships it first, or guess at roadmaps. The part I can defend: the axis that decides this fight is update friction, and the asymmetry is real today. MCP closes the gap between “the maintainer fixed it” and “the user has the fix” to zero. Skills, by default, do not.
If that sounds familiar, it should. We watched the same film in 2007.
In June 2007 the iPhone shipped with no native SDK. Jobs told developers the way to build for it was web apps in Safari, so for a year the web was the only distribution channel on the hottest new platform going. Then in 2008 the App Store shipped a native SDK and native exploded, not because the web got worse, but because native captured the channel: the store, the install button, push. The “web versus native” war ran from 2007 to 2013, “HTML5 is the future” peaked, and in 2012 Facebook retreated to native and Zuckerberg called the HTML5 bet the company’s biggest mistake. That fight was not decided by which technology rendered a button better. It was decided by who controlled the update channel.
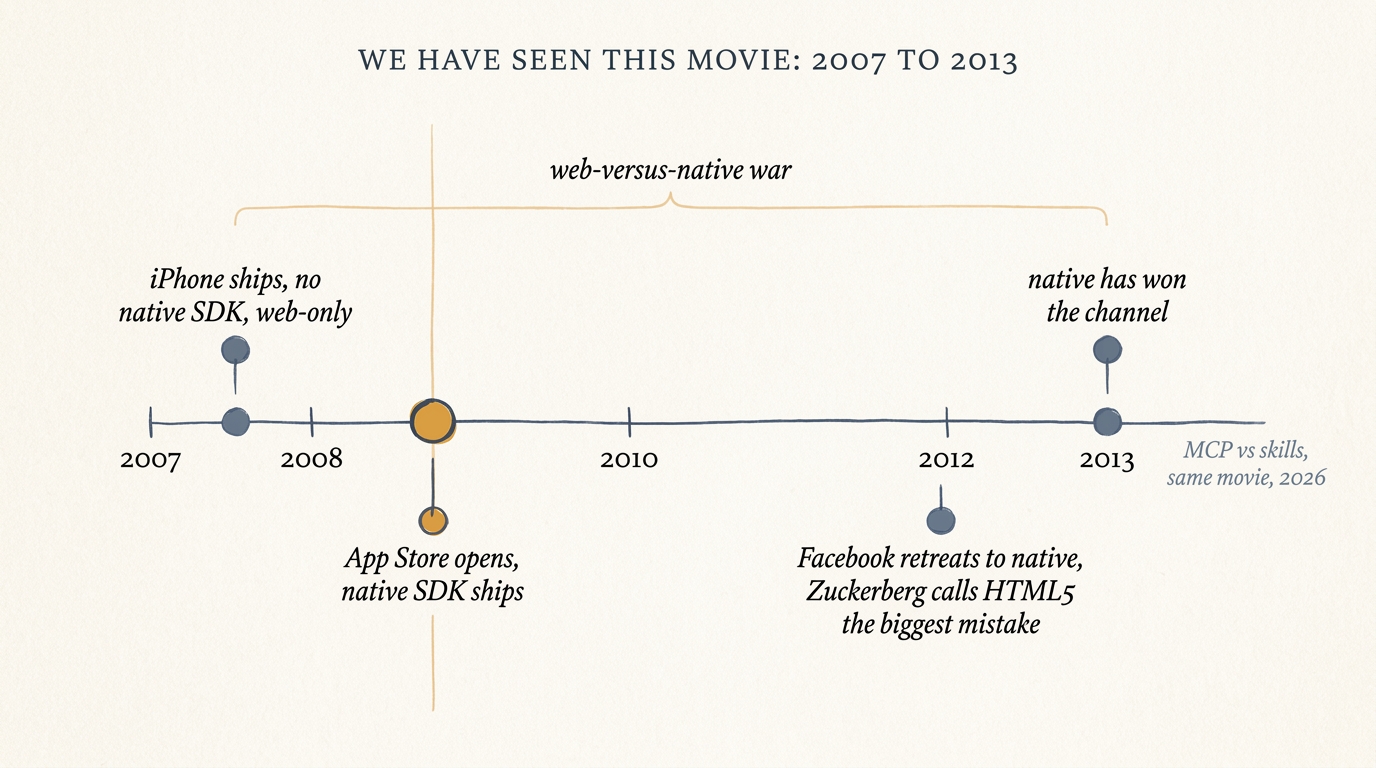
The 2007 web-versus-native fight, plotted. The amber pivot is the moment the store captured the channel; the note at the right is where MCP and skills sit in the same story.
MCP versus skills is the same movie, new actors. The platform that controls the update button wins, and right now, on the axis that decides it, that is MCP.
May the force, and the update button, be with you…