AI Agent Workflow: 13 Documents for a Label Change
Table Of Contents
Let me tell you how I perfected my AI agent workflow. Actually, no—let me tell you how I destroyed it.
But first, the backstory. This was the pre-ChatGPT era. I had the best team I ever worked with: a backend team, two QAs, two Flutter devs, a BA, and a tech lead running the show. The workflow was beautiful: we’d get a spec, write a technical implementation plan, build the APIs. QA would test once we declared “done.” They filed bugs—sometimes blockers, sometimes discussion markers we’d reference years later (“Why did we do that again?”). Once QA signed off, we’d have a handover call with mobile devs who’d implement against our APIs.
The blast radius was contained. If the API failed, all clients failed. But if a client failed? That was their problem, not ours. Clear boundaries. Clean handoffs. Everyone knew their role.
So naturally, when AI agents entered my workflow, I thought: I should recreate this. With subagents.
What could go wrong?
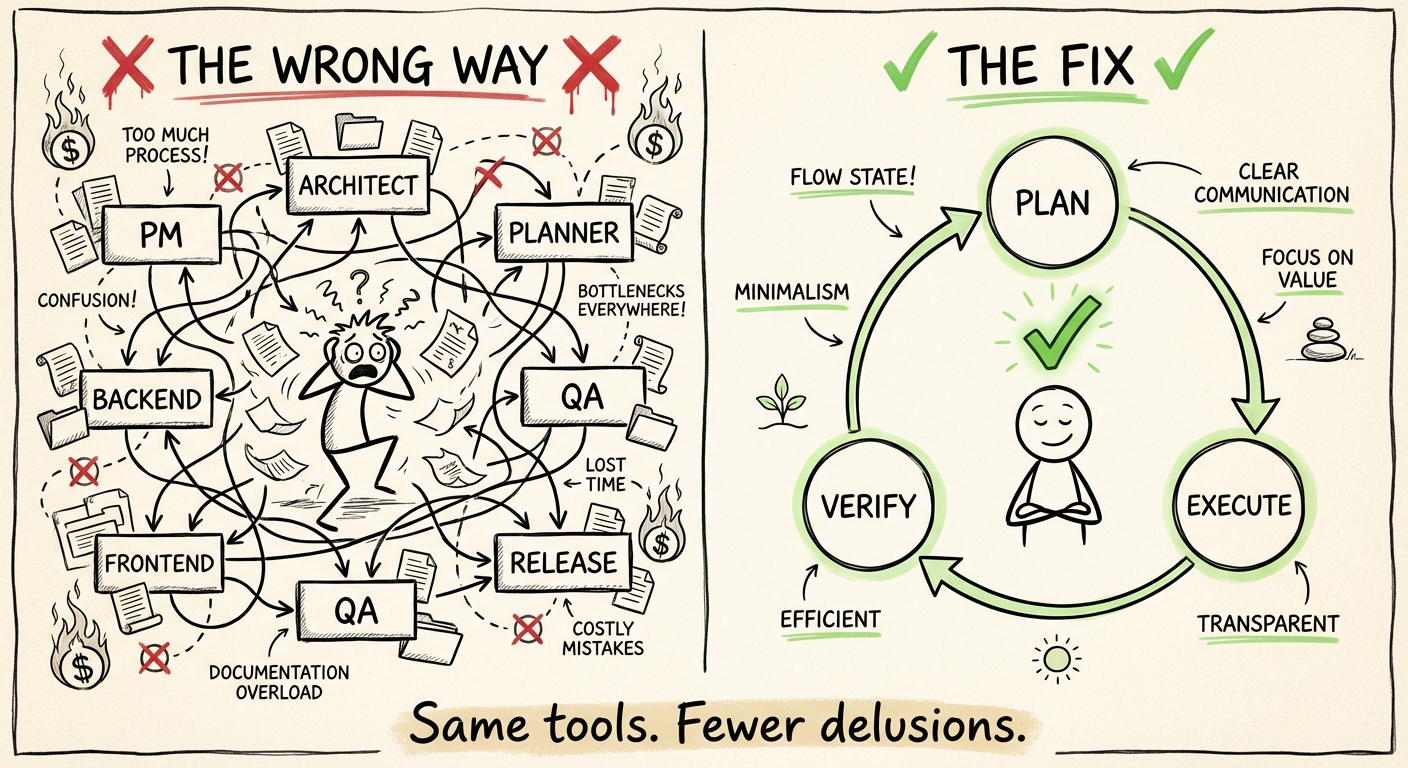
Step 1: build an entire AI team (maximum overhead)
Here’s the dream setup I architected:
PM → Architect → Planner → Backend Worker → QA → Frontend Worker → QA → Release
And me at every step—orchestrating, reviewing, approving. Like a proper tech lead.
This was me mimicking the best team I ever had. The one that shipped efficiently, communicated well, knew their roles. That team ended six months before ChatGPT launched. But surely, I could recreate 2022’s magic with 2024’s tools?
If you want to maximize your token spend, this is the way. Trust me.
Step 2: ignore context completely (subagents love starting fresh)
Here’s something I discovered about Claude Code subagents: they start with zero context by default.1
Zero. Zilch. Nothing.
Your main chat reads a file? The subagent reads it again. Your architect creates a plan? The worker has no idea it exists. Your QA files a bug? The developer subagent stares at you blankly, waiting for you to explain what a “bug” is.
It’s like hiring a new contractor for every task and expecting them to know your codebase, your conventions, your inside jokes. Every. Single. Time.
The context duplication is magnificent. Your token counter spins like a slot machine—except you always lose.
Step 3: generate documents nobody will read (the slop accelerator)
Here’s where Conway’s Law enters the chat.
Melvin Conway observed in 1967 that “organizations produce systems mirroring their communication structures.” If your org has four approval layers, your software will have four approval layers. If your team is siloed, your architecture will be siloed.
Now, apply this principle to AI agents.
If your human workflow needs four approvals before changing a font on the website, congratulations: your AI agents will accelerate producing those four approval documents. They won’t question the process. They won’t push back. They’ll dutifully generate Document 1, Document 2, Document 3, and Document 4—each one longer than the last, each one more comprehensive than anyone asked for.
And unless you religiously follow those docs, they’re just slop. Very expensive slop.
(Though yes, you probably do need four well-thought approvals before migrating your NoSQL database from Redis to DynamoDB. And at least one buy-in before changing your cache to Redis. The trick is knowing the difference—and AI agents don’t know the difference. They just produce.)
The confession: $10 and 13 documents for a label change
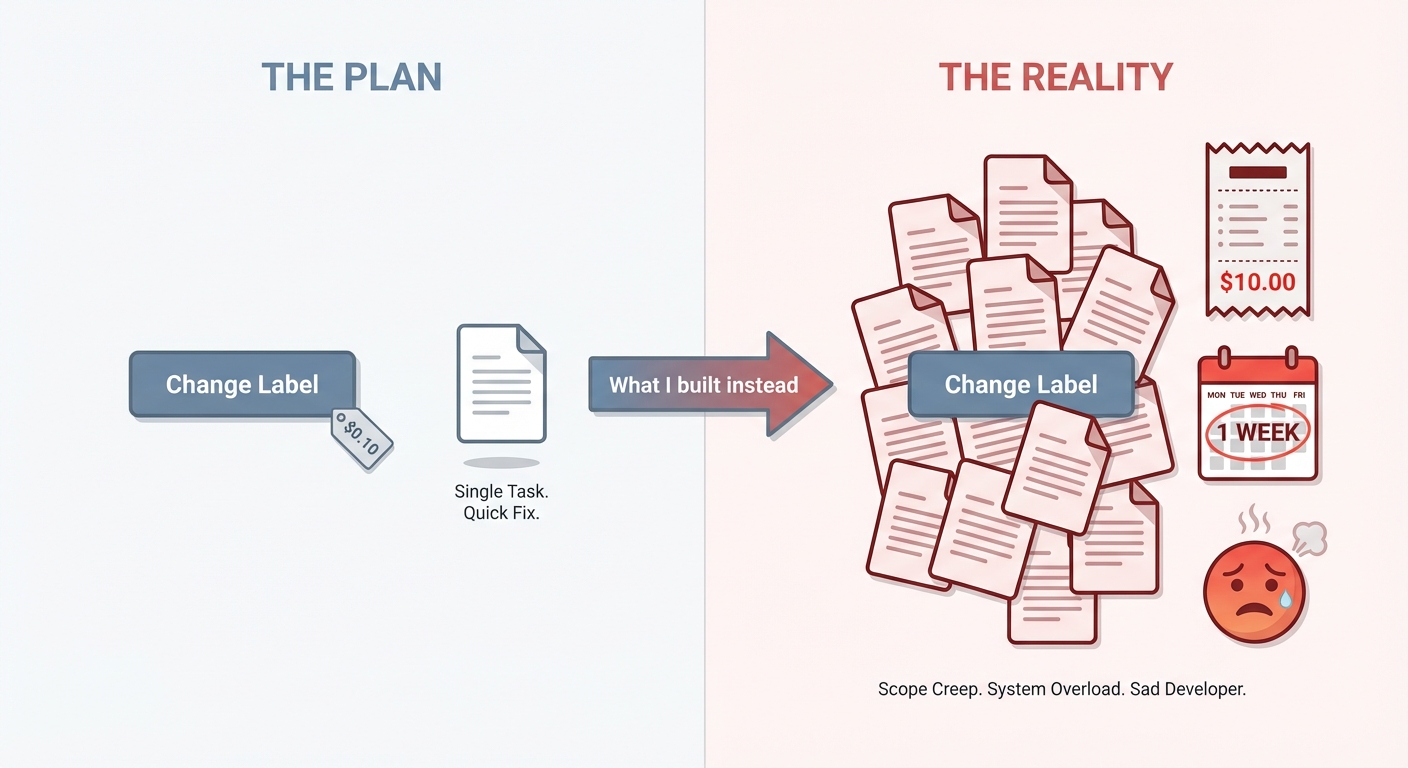
Let me be specific about my failure.
For a simple fullstack change—one CRUD API and a simple page—my beautiful AI team generated 10-13 documents. Ten to thirteen reports. For a CRUD endpoint and a label.
I spent more than a week on this. The agents worked exactly as designed: PM analyzed requirements, Architect designed the solution, Planner broke it into tasks, Workers executed, QA validated. Every step documented. Every handoff formalized.
It was like hiring a dev shop that charges six days for a label change. Except I was both the client and the architect of my own misery.
Cost? About $10 in API tokens. Time? A week of my life I won’t get back. Satisfaction? Like flipping a coin—and losing.
Why this happens: Conway’s Law, but make it AI
The uncomfortable truth is that I structured my agents like a bureaucratic team, and consequently, I got bureaucratic outputs.
My 2022 team worked because humans have persistent memory. We didn’t need handover documents for every interaction—we remembered last week’s decisions. We built shared context over months. Our “documents” were actually decision logs we referenced, not process artifacts we generated and forgot.
However, AI agents don’t work this way. Each subagent invocation creates a new instance. No shared memory. No “hey, remember when we decided X?” No accumulated team knowledge.
So what did my agent team produce? Documents. Lots of documents. Because that’s the only way to pass context when you’ve structured your workflow around amnesia.
The documents reflect human nature. Or more precisely, they reflect organizational nature. And I had built an organization optimized for documentation, not for shipping.
Fixing my AI agent workflow (what actually works)
Consequently, after burning through tokens and sanity, I went back to basics.
AI agents have three essential loops: Plan → Execute → Verify.
That’s it. Not PM → Architect → Planner → Backend → QA → Frontend → QA → Release. Just three steps, with a human in the loop where it matters.
I tweaked my workflow to identify complexity levels first. Simple changes don’t need architectural reviews. Label changes don’t need 13-document approval chains. The model is smart enough to execute simple tasks simply—if you let it.
As a result, even my most complex feature (admin-gating an MCP server) now has max 4 documents. One of them is just two commits in a txt file. Sometimes 5 when I ask for a walkthrough.
From 13 to 4. Same tools. Same models. Fewer delusions of grandeur. (I wrote more about this journey in my post on AI agent configuration debt—the rot runs deeper than workflows.)
The spec-kit temptation
GitHub recently open-sourced spec-kit, a toolkit for “Spec-Driven Development.” Four phases: Specify → Plan → Tasks → Implement. Support for 16+ AI agents. Constitutional principles governing implementation.
Part of me looks at spec-kit and thinks: This is the formalized version of the bloat I created manually.
That said, spec-kit is designed thoughtfully. It has guardrails. It knows when to apply heavy process and when to skip it. The “nine articles” constitutional framework actually makes sense for complex projects.
But I can already see the failure mode: someone will use spec-kit for everything. Every feature. Every bug fix. Every label change. And they’ll generate beautiful, comprehensive, perfectly structured documentation that nobody will ever read.
The tool isn’t the problem. The problem is thinking that more process equals better outcomes.
The inverse Conway maneuver
Ultimately, here’s the real lesson.
If Conway’s Law says organizations produce systems mirroring their structure, then the inverse is also true: you can deliberately structure your “organization” (or agent workflow) to produce the architecture you want.
Want lean, fast outputs? Structure your agents for lean, fast work. Don’t recreate your 2022 team hierarchy. Don’t add approval gates because “that’s how software development works.” Don’t build bureaucracy and expect efficiency.
Ask yourself:
- Do I need a PM agent, or can I just… write the requirements myself?
- Do I need an Architect agent, or does the model already know how to structure code?
- Do I need a QA agent, or can I verify the output myself in less time than it takes to explain the verification criteria?
Every agent you add is context you duplicate. Every handoff is information you lose. Every formal process is tokens you burn.
The uncomfortable truth
I tried to recreate the best team I ever had—with AI.
But that team worked because of humans. Persistent memory. Shared context. The ability to say “you know what I mean” and actually have the other person know what you mean.
AI agents aren’t humans. They don’t remember. They don’t accumulate. They process inputs and produce outputs, and if your inputs are bureaucratic, your outputs will be too.
The fix isn’t better agents. It’s fewer layers. Simpler structures. Human judgment where it matters, AI execution where it doesn’t. (This is also why configuration matters as much as capability—wrong setup, wrong results.)
Plan. Execute. Verify. Human in the loop. That’s the workflow.
My current setup? Four documents, max five: a Plan, a CommitHash file, validation reports (one for backend, one for frontend), and occasionally a walkthrough when I need to understand what happened. That’s it. No PM analysis. No architect review. No approval chains.
Everything else is expensive documentation practice.
(In the next post, I’ll break down exactly how this Plan→Execute→Verify loop works in practice—where the human checkpoints go, what each document actually contains, and why fewer artifacts means faster shipping.)
May the force be with you…
Been down this path yourself? I’d love to hear your AI workflow horror stories—especially the ones where you realized the problem was the process, not the tools. The usual channels work.
Unless you explicitly design handover mechanisms, which I didn’t, because why would I read the documentation when I could just assume things work like human teams? ↩︎